刚刚,DeepSeek公布推理时Scaling新论文,R2要来了?
文章摘要
【关 键 词】 强化学习、奖励模型、推理扩展、自我原则、在线学习
DeepSeek与清华大学的研究人员提出了一种名为自我原则批评调整(SPCT)的新方法,旨在提升通用奖励模型(GRM)在推理阶段的可扩展性。该方法通过结合拒绝式微调和基于规则的在线强化学习,使GRM能够自适应地生成高质量的原则和批评,从而在一般领域获得更好的奖励信号。SPCT的核心创新在于将准则生成与奖励生成紧密结合,使模型能够在推理过程中动态生成并应用准则,显著提升了奖励模型的泛化能力和推理效率。
在技术实现上,SPCT分为两个阶段:首先是拒绝式微调,作为冷启动阶段,确保GRM能够生成格式正确且适配多种输入类型的原则与批评;其次是基于规则的在线强化学习,通过不断优化生成的准则和评论,进一步增强GRM的泛化能力。这一框架使得GRM能够在推理阶段展现出良好的扩展能力,尤其是在处理复杂任务时,能够通过生成大量原则和批评来提高奖励的准确性和多样性。
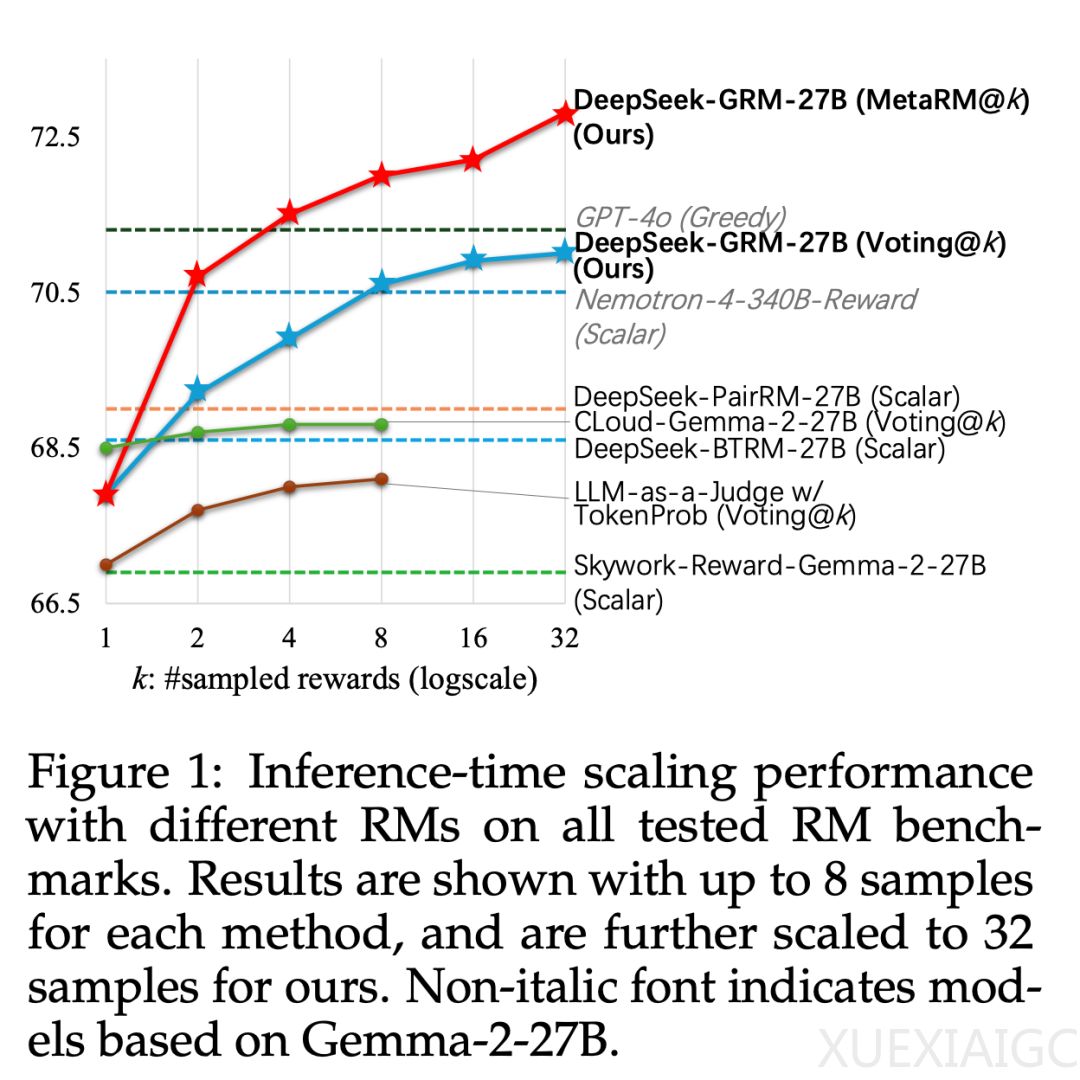
基于SPCT,DeepSeek开发了DeepSeek-GRM-27B模型,该模型通过多次采样和并行计算来扩展推理时间的使用量,并通过投票机制选出最终的奖励。实验结果表明,SPCT在生成质量和推理阶段的可扩展性方面明显优于现有方法,并且在多个综合奖励模型基准测试中表现优异,没有出现严重的领域偏差。此外,研究者还引入了一个元奖励模型(meta RM),用于指导投票过程,进一步提升了奖励生成的质量。
研究还发现,SPCT的训练方案在更大规模的语言模型上同样有效,推理阶段的扩展性收益甚至超过了通过增加模型规模所带来的训练效果提升。这表明,SPCT不仅能够提升现有模型的性能,还为未来更大规模模型的训练和推理提供了新的思路。
总体而言,这项研究为通用奖励模型的推理时间扩展提供了新的解决方案,并通过实验验证了其有效性。SPCT的提出不仅推动了强化学习在大语言模型中的应用,还为未来更高效、更灵活的奖励系统设计奠定了基础。
原文和模型
【原文链接】 阅读原文 [ 2787字 | 12分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek-v3
【摘要评分】 ★★★★★


相关文章



