文章摘要
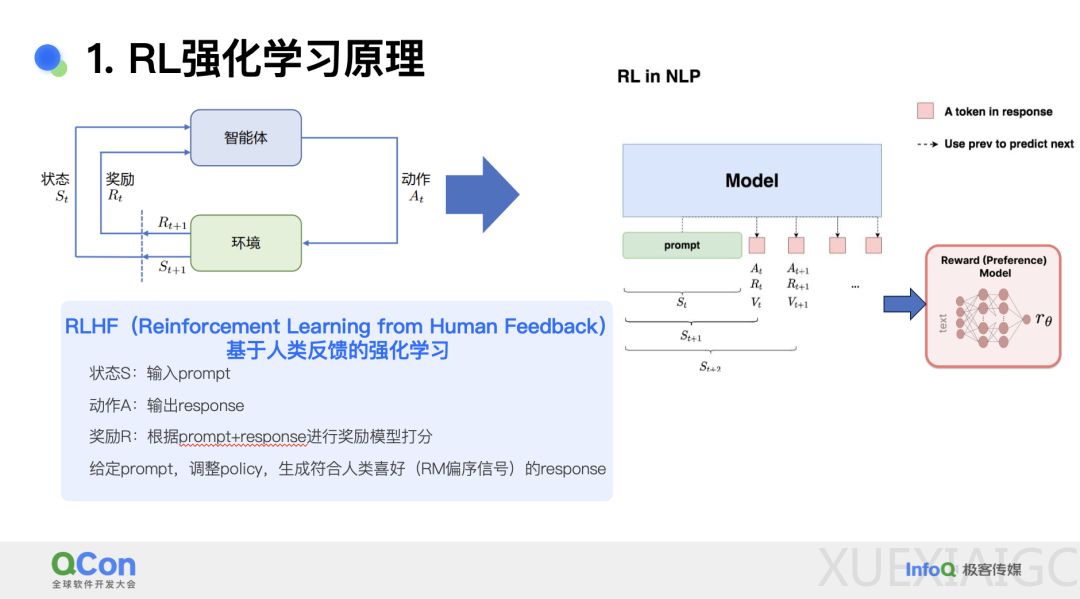
随着大模型技术从技术变革转向产业变革,传统基础设施技术已无法满足大模型应用的快速发展需求,整个基础设施技术和产业链正在向大模型基础设施技术转型。多模态模型是当前 AI 领域的热门研究方向,其通过大规模预训练获得图文理解、创作、知识推理等能力,并通过基于人类反馈信号的强化学习(RLHF)进一步优化模型效果。PPO(Proximal Policy Optimization)算法是 OpenAI 在 RLHF 阶段采用的核心算法,其设计和实现高效、准确的 RLHF 训练系统是多模态模型研究的关键挑战之一。
在 2024 年 QCon 上海站上,小红书资深技术专家于子淇分享了其团队自研的 MLLM RLHF 训练框架及其性能优化实践。RLHF 的核心流程包括奖励模型(RM)和强化学习(RL)过程,其中 RM 通过人类专家对模型输出的排序数据进行训练,而 RL 则采用 PPO 策略梯度算法进行在线样本生成和实时更新。PPO 算法涉及演员模型、评论家模型、奖励模型和参考模型四个模型的协同训练和推理,其训练流程包括经验采样和训练迭代两个主要步骤。
小红书团队设计的 RLHF 框架通过训推混布、异构组网架构和同构组网架构优化了训练和推理性能。异构组网架构通过模型复用和异步训练提升了 50% 的性能,而同构组网架构则进一步减少了模型数量,降低了推理成本。在训练性能优化方面,团队采用了数据预读取、并行优化策略、显存优化和负载均衡等技术,显著提升了训练效率。流水线优化方面,通过训推混布和流水线并行,训练耗时从 2250 秒减少到 690 秒。
PPO 细节处理中,团队通过 Padding-free、参数同步、CP 并行和 Logp 实现进一步优化了性能。多模态模型的优化则通过组网优化、多路复用和预读取优化实现了与 LLM 相当的性能表现。训推一致性方面,团队通过复用网络结构和本地 offload 实现保证了训练和推理的精度一致。
Medusa 算法的引入通过投机采样提升了生成效率,生成速度提升了 50%。实践案例显示,新的 RLHF 框架显著提升了模型的推理、创作、问答、数学、对话和代码能力,综合提升达 6%。此外,PRM 效果的提升也改善了模型回答问题的可解释性和激励粒度。
未来,团队计划进一步优化性能,探索去掉 RLHF 人工奖励部分的算法,结合 RL-COT 打造更深层的推理能力,实现真正的 RL scaling-law。于子淇作为小红书 RLHF 自研框架负责人,其团队在 RLHF 系统构建和训推一体性能优化方面取得了显著成果,为 AI 大模型的应用落地提供了重要支持。
原文和模型
【原文链接】 阅读原文 [ 4250字 | 17分钟 ]
【原文作者】 AI前线
【摘要模型】 deepseek/deepseek-v3/community
【摘要评分】 ★★★★★


相关文章



