文章摘要
【关 键 词】 稀疏注意力、长文本处理、模型训练、框架优化、团队协作
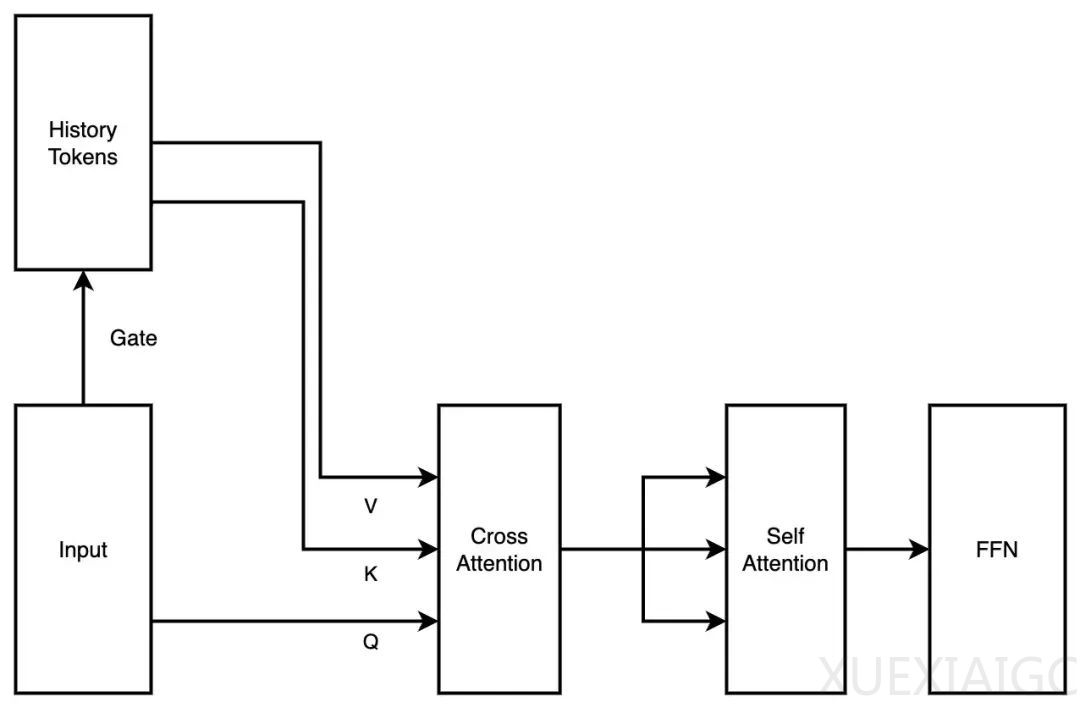
月之暗面团队于2023年5月启动MoBA框架研发,旨在提升大语言模型处理长文本的效率与兼容性。该框架结合稀疏注意力与分布式训练技术,支持上下文长度扩展至10M,并实现全注意力与稀疏注意力模式的无缝切换。核心目标是通过端到端训练解决长文本建模的Token效率问题,同时兼容现有预训练模型。初期设计的MoBA v0.5采用串行双层注意力结构,整合MoE理念与Context Parallel技术,将上下文序列分布至数据并行节点,通过跨节点通信实现稀疏计算。然而,随着模型规模扩大,参数增加导致训练成本过高,项目首次进入优化阶段(“一入思过崖”)。
在第一次改进中,团队将结构简化为并行单层注意力方案(MoBA v1),减少额外参数并支持继续训练。尽管在3B、7B模型上验证有效,但更大规模模型训练中出现严重损失波动,暴露出块注意力输出合并方式的缺陷。通过引入Online Softmax技术,团队实现了稀疏度可调的全注意力对照调试,解决了数学等价性问题。然而,Context Parallel设计引发的计算负载不均衡(即Attention Sink现象)促使第二次深度优化(“二入思过崖”)。章老师提出的Context Parallel与MoBA解耦方案,使框架回归稀疏注意力本质,最终形成MoBA v2——在单机处理上下文的基础上,通过分布式组织提升加速效率,并实现与全注意力的指标对齐。
上线前测试发现,SFT阶段稀疏损失掩码导致长文总结任务效率骤降。团队通过将最后几层切换为全注意力模式,显著提升梯度传播密度,在不影响稀疏效果的前提下解决了特定任务性能瓶颈。经历三次“思过崖”迭代后,MoBA v2成功部署,支持1M长度下与全注意力模型性能持平,并通过了严格的“捞针测试”。
技术细节方面,MoBA对解码阶段的影响因注意力头类型而异:对MHA(多头注意力)优化效果显著,但对GQA(分组查询注意力)和MQA(多查询注意力)的IO优化可能被共享KV缓存抵消。框架采用极简设计,未强制包含邻近块注意力,依赖模型自主学习选择模式。尽管尝试过Triton实现性能提升,但因维护成本过高暂未采用。最终开源的MoBA代码已通过工业级验证,为长文本处理提供了高效可扩展的解决方案。
原文和模型
【原文链接】 阅读原文 [ 2998字 | 12分钟 ]
【原文作者】 AI产品阿颖
【摘要模型】 deepseek-r1
【摘要评分】 ★★★★☆


相关文章



