文章摘要
【关 键 词】 AI语音合成、小说演播、Seed-TTS、端到端模型、语音技术改进
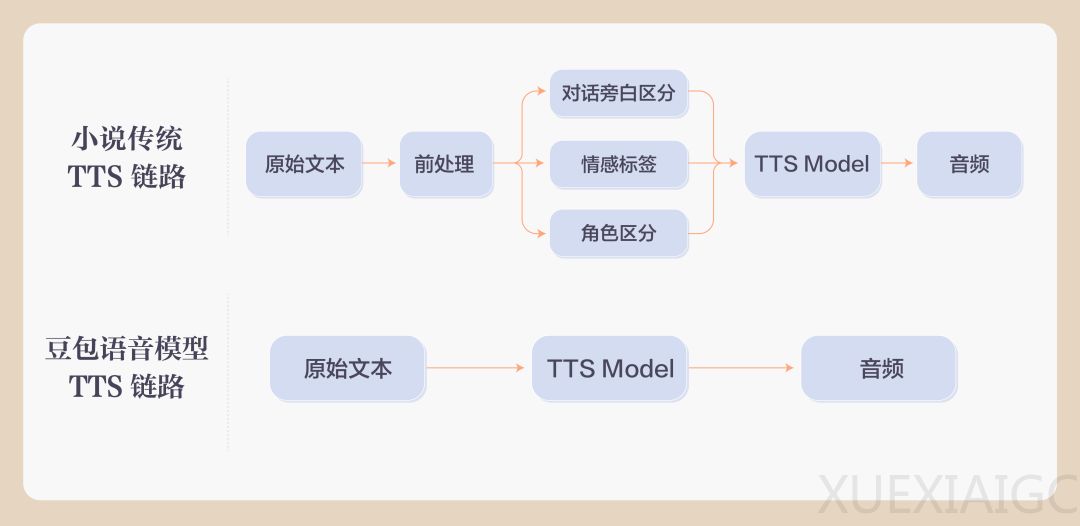
豆包语音模型团队通过技术革新实现了AI合成语音在小说演播场景的突破性进展。基于改进的Seed-TTS框架,该系统无需人工标注标签即可端到端生成高自然度语音,在保留原始文本语义的同时,显著提升了角色区分度与情感表现力。相较于传统语音模型需要预先标注对话旁白、情感和角色的繁琐流程,新技术通过全自动处理大幅提升了效率。
该模型在原始Seed-TTS架构基础上进行了多维优化:采用章节级音频处理保障长文本连贯性,融合音素、音调、韵律等多维度特征提升发音准确性,将语音标记器改为说话人嵌入以突破参考音频的风格限制。尤为关键的是引入上下文理解机制,使模型能捕捉更大范围的语义信息,从而实现旁白与角色音色的精准匹配。专业评测显示,优化后的合成语音CMOS评分已达真人主播水平的90%以上。
技术落地方面,团队与知名演播艺术家合作开发的千部有声书已上线番茄小说平台,覆盖历史、悬疑、科幻等主流题材。通过消除传统语音合成对参考音频的依赖,同一发音人可灵活适配不同角色设定,显著提升了多角色小说的听觉体验。未来该技术将持续探索语义理解与语音合成的深度融合,致力于打造更自然流畅的智能听书解决方案。
原文和模型
【原文链接】 阅读原文 [ 905字 | 4分钟 ]
【原文作者】 量子位
【摘要模型】 deepseek-r1
【摘要评分】 ★☆☆☆☆

© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章

暂无评论...


