文章摘要
AMD在官网开源了最新的小参数模型Instella-3B,该模型基于AMD Instinct™ MI300X GPU从头训练,展现了AMD GPU在训练高性能大模型方面的潜力。Instella-3B的性能超越了Llama-3.2-3B和Gemma-2-2B,并与阿里开源的Qwen-2.5-3B相当,证明了其在开源模型中的竞争力。该模型的开源地址为https://huggingface.co/amd/Instella-3B,提供了Instella-3B-SFT和Instella-3B-Instruct两个版本,分别经过监督微调和直接偏好优化,以增强指令遵循和聊天能力。
Instella-3B基于自回归Transformer架构,拥有30亿参数,包含36个解码器层,每层有32个注意力头,支持最长4096 tokens的序列长度,词汇量约为50,000 tokens。在训练过程中,AMD采用了FlashAttention-2、Torch Compile和bfloat16混合精度训练技术,以减少内存使用并提高计算效率。此外,AMD还使用了全分片数据并行(FSDP)与混合分片技术,优化了集群内节点间的内存效率和通信开销。
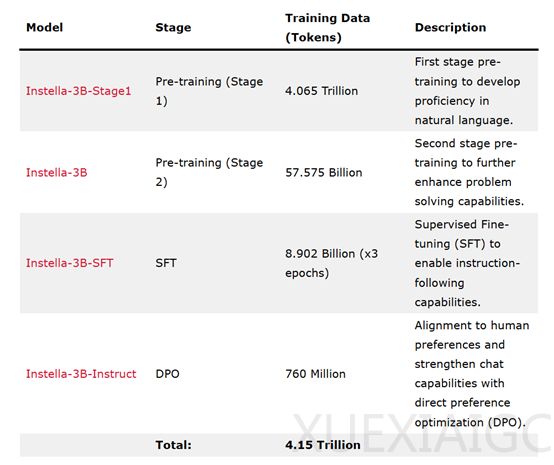
模型的训练分为四个阶段,逐步增强其自然语言理解、指令遵循和人类偏好对齐能力。在第一阶段预训练中,AMD使用了4.065万亿tokens的数据,涵盖编码、学术、数学和网络爬取等领域,为模型奠定了自然语言理解的基础。第二阶段预训练使用了额外的575.75亿tokens数据,包括高质量和多样化的数据集,如Dolmino-Mix-1124、SmolLM-Corpus、Deepmind Mathematics以及对话数据集等,进一步提升了模型的性能。此外,AMD还使用了内部合成数据集,专注于数学问题,通过生成Python程序解决问题并替换数值,生成新的问题-答案对,使模型在多个基准测试中表现出色。
在指令微调阶段,AMD使用Instella-3B作为基础模型,使用89亿tokens的高质量指令-响应对数据进行了三个周期的训练,增强了模型在交互式环境中的表现,使其更适合执行用户指令的任务。最后的对齐阶段,AMD使用直接偏好优化(DPO)技术,以Instella-3B-SFT为基础模型,使用7.6亿tokens的数据进行训练,确保模型的输出符合人类价值观和期望,从而提高其输出的质量和可靠性。
Instella-3B在多个基准测试中超越了现有的全开源模型,例如在MMLU、BBH和GSM8k等测试中,其表现优于Llama-3.2-3B和Gemma-2-2B。经过指令微调和对齐后的Instella-3B-Instruct模型在指令遵循任务和多轮问答任务中表现出色,同时在训练数据量上更少,展现了其高效性和实用性。
原文和模型
【原文链接】 阅读原文 [ 912字 | 4分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 deepseek-v3
【摘要评分】 ★★☆☆☆


相关文章



