文章摘要
【关 键 词】 大模型、写作评估、生成式AI、思维链、动态评估
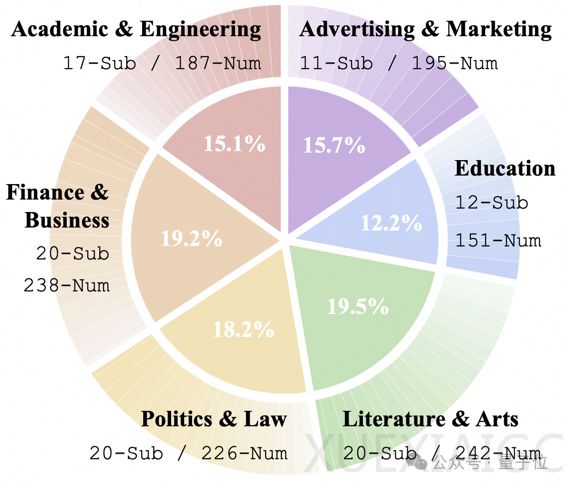
阿里研究团队联合中国人民大学和上海交通大学共同开发了WritingBench,这是一个全面评估大模型生成式写作能力的基准。该基准覆盖了六大领域和100个细分场景,包含1000多条评测数据,旨在为生成式写作提供全面的评估。团队发现,基于Qwen开发的32B创作模型在创意型任务上表现接近顶尖模型R1,为高效能创作开辟了新路径。
目前,行业在评估大模型写作能力时面临两大难题。首先,现有AI写作评估多局限于单一领域和短文本,导致真实场景中模型表现不尽如人意。其次,传统评估方法多采用固定标准来衡量创意写作、法律文书等复杂场景,与人类判断的一致性不足65%。针对这些挑战,WritingBench从现实需求中提炼出六大场景,并进一步细分为100个子类,采用四阶段人机协同构建评测集。团队耗时三个月,经过四个阶段流程完成评测集构建,确保评测集覆盖广泛且具有深度。
WritingBench设计了一种基于写作意图自动生成评测指标的方法,模型可以针对每个写作输入自动生成五个评测指标的名称、描述和评测细则。这种动态评估策略实现了87%的人类一致性得分。团队还配套训练了一个评分模型,能够根据不同指标自适应地给出1-10分的评分及具体理由。例如,在评估OpenAI提供的示例时,评估包括「元小说技巧」、「AI视角真实性」、「悲伤主题发展」、「文学艺术性」、「人工智能和悲伤的主题整合度」五个维度。
在生成式写作的未来发展方向上,团队探讨了思维链在创意写作中的有效性。实验发现,在32B规模的模型中,带思维链的模型表现优于不带思维链的模型。然而,在效率型写作任务上,深度思考的效果并不显著,且存在过度推理的问题,容易导致编造数据和产生幻觉。此外,实验揭示大模型依旧面临显著的长度生成瓶颈,当输出长度超过3000 token时,大部分模型的质量显著下降。
目前,该项目已经开源,相关论文和模型可在GitHub和Hugging Face上获取。WritingBench的推出为大模型生成式写作能力的评估提供了新的标准和工具,有望推动该领域的进一步发展。
原文和模型
【原文链接】 阅读原文 [ 2063字 | 9分钟 ]
【原文作者】 量子位
【摘要模型】 deepseek-v3
【摘要评分】 ★★★★★


相关文章



