Sebastian Raschka:关于DeepSeek R1和推理模型,我有几点看法
文章摘要
【关 键 词】 推理模型、强化学习、监督微调、模型蒸馏、训练流程
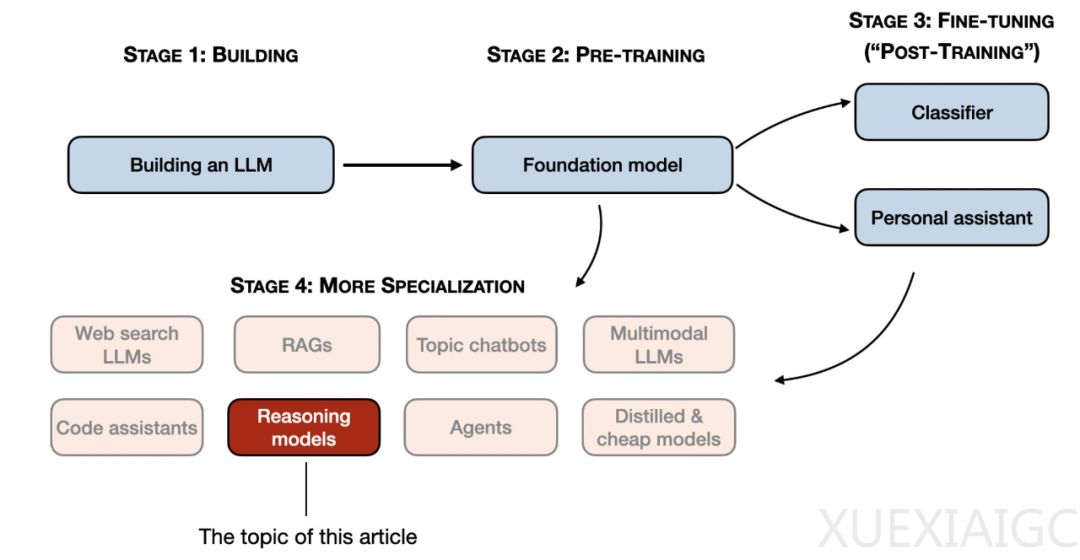
著名AI研究者Sebastian Raschka基于DeepSeek技术报告,系统阐述了增强大语言模型推理能力的四大核心方法。_推理模型被定义为擅长处理需要多步骤中间推导的复杂任务(如数学证明、编程难题)的LLM,其响应中通常包含显式或隐式的思维过程_。这类模型在演绎推理、复杂决策任务中表现突出,但存在响应速度慢、简单任务易”过度思考”等局限性。
DeepSeek R1系列模型的开发流程揭示了专业化推理模型的构建路径。_通过纯强化学习(RL)首次观察到模型涌现出推理能力,在未使用监督微调(SFT)的情况下,模型自主生成包含中间步骤的响应_。旗舰模型DeepSeek-R1采用SFT+RL混合策略:先利用RL模型生成冷启动SFT数据,再通过多轮SFT与RL迭代优化,最终在编程和数学任务准确率上超越同类模型。实验表明,RL与SFT的协同作用能显著提升模型性能,而纯RL训练更适用于探索推理能力的涌现机制。
推理时间扩展作为无需修改模型结构的重要补充手段,通过增加计算资源提升输出质量。_思维链提示和多数投票等策略虽增加推理成本,但能有效引导模型生成更可靠的推理过程_。OpenAI的o1模型被推测结合了该技术与RL训练,而DeepSeek则通过优化训练流程实现更高推理效率。值得注意的是,模型蒸馏为低成本开发提供了可行路径——基于大模型生成的SFT数据微调小模型,可使32B模型以450美元成本达到接近顶级模型的推理水平。
不同方法的适用场景呈现明显差异:纯RL适合理论研究,SFT+RL组合是高性能模型的首选方案,蒸馏技术则平衡了效率与成本。_DeepSeek-R1的开放权重特性及其详细技术报告,为理解推理模型训练范式提供了宝贵案例_。研究同时揭示,当模型参数量低于32B时,蒸馏效果优于纯RL训练,这为资源有限的研究者指明了优化方向。
成本效益分析显示,推理模型开发需权衡训练投入与推理效率。DeepSeek-R1虽需数百万美元级训练成本,但其开放协议和高效推理架构降低了应用门槛。相比之下,基于现有模型的定向微调方案,仅需数百美元即可获得专业推理能力,这为中小规模团队参与前沿研究开辟了新可能。未来趋势将聚焦于RL训练与推理扩展技术的深度融合,以及更精细化的成本控制策略。
原文和模型
【原文链接】 阅读原文 [ 6619字 | 27分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek-r1
【摘要评分】 ★★★★★


相关文章



