YOLO已经悄悄来到v12,首个以Attention为核心的YOLO框架问世
文章摘要
【关 键 词】 目标检测、注意力机制、YOLOv12、实时性、计算优化
YOLOv12通过引入创新的注意力机制和结构优化,显著提升了实时目标检测的性能与效率。该模型由纽约州立大学布法罗分校和中国科学院大学的研究团队联合开发,旨在解决传统注意力机制因计算复杂度和内存访问效率问题难以应用于YOLO框架的长期挑战。其核心突破在于提出的区域注意力模块(A2)和残差高效层聚合网络(R-ELAN),在保持大感受野的同时实现了计算效率的平衡。
区域注意力模块(A2)通过将特征图划分为纵向或横向区域,将注意力计算复杂度从O(n²)降低至O(n²/k²),其中默认分割数k=4。这种方法仅需简单的reshape操作,避免了局部注意力机制的显式窗口划分开销。实验表明,A2模块在COCO数据集上仅造成0.2-0.5%的mAP损失,却使计算速度提升2.1倍,为实时检测任务提供了有效的注意力替代方案。同时,R-ELAN通过引入块级残差连接和瓶颈式特征聚合结构,解决了大规模模型训练中的梯度阻塞问题,其缩放因子(0.01)设计进一步优化了梯度流动。
在架构改进方面,研究团队采用分层设计保留YOLO主干网络特性,通过四项关键调整提升效率:使用FlashAttention优化显存访问,移除位置编码并采用7×7可分离卷积感知位置信息,将MLP比率从4降至1.2以平衡计算分配,以及减少主干网络末端的堆叠块数量。这些调整使模型在640×640分辨率下实现1.64ms/图像的推理速度,同时参数量减少最高达37.1%。
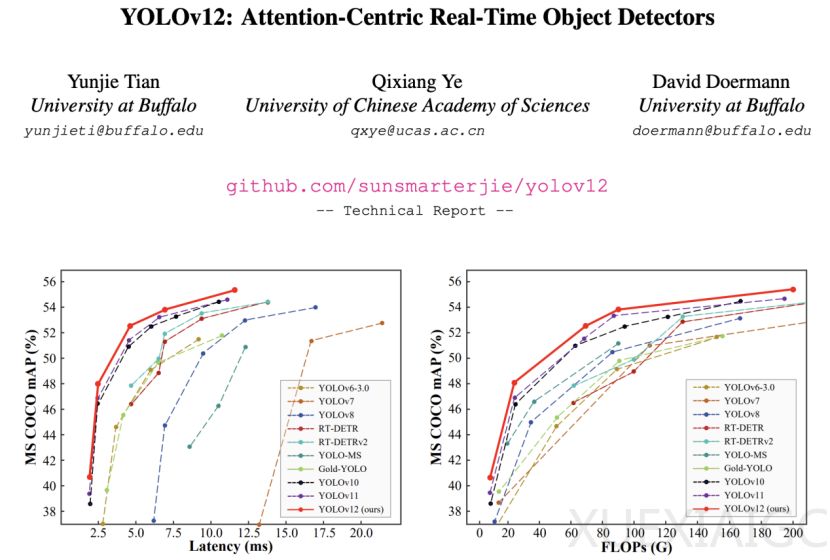
实验数据显示,YOLOv12在不同规模模型上均展现优势。以X-scale模型为例,其mAP较YOLOv10-X提升0.8%,计算量减少23.4%,参数量降低22.2%。在CPU(Intel i7-10700K)测试中,YOLOv12的推理速度比同类模型快1.3-2.4倍,热力图分析显示其激活区域更精确,目标轮廓清晰度提升显著。可视化对比表明,区域注意力机制使模型获得更大的有效感受野,增强了全局上下文捕捉能力。
该研究通过系统性的结构创新,首次在YOLO框架中成功整合注意力机制,在COCO数据集上实现52.5% mAP(M-scale模型)的同时保持4.86ms/图像的实时性能,为实时目标检测领域提供了新的技术路径。研究团队开源了代码与预训练模型,推动相关技术的进一步发展与应用。
原文和模型
【原文链接】 阅读原文 [ 2225字 | 9分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek-r1
【摘要评分】 ★★★★★


相关文章



