文章摘要
【关 键 词】 MoE模型、门控网络、计算效率、专家系统、深度学习
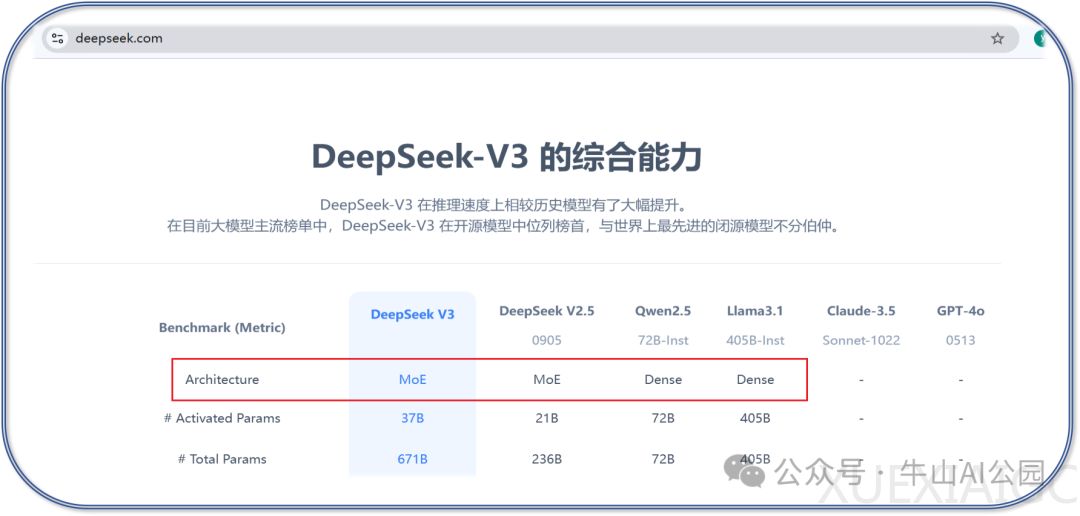
混合专家模型(MoE)通过选择性激活子模型的方式显著提升计算效率,与传统Transformer架构形成鲜明对比。MoE模型每次计算仅激活5.5%的总参数量,而Qwen、LLama等传统模型需全量参数参与运算,这种差异源于MoE独特的门控机制与专家网络协同架构。其核心组件包含门控网络和若干专家网络,前者通过概率分布动态分配输入任务,后者由专业化子模型构成,形成类似”专家会诊”的决策模式。
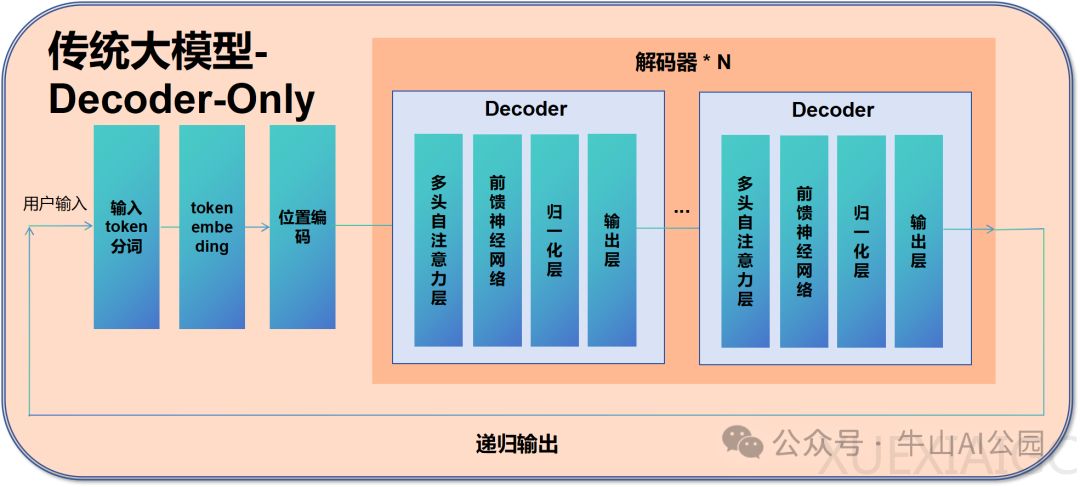
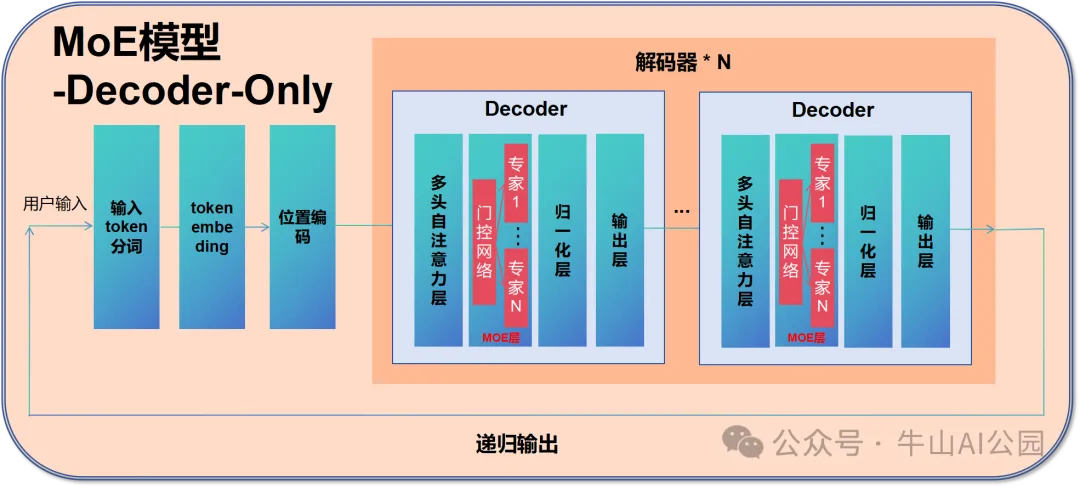
在模型结构层面,MoE将传统Transformer的前馈网络层替换为MoE层。门控网络通过Top-k选择策略(通常k=2-4)激活特定专家,仅对选中专家进行权重计算。以情感分析任务为例,当输入”开心”这类情感词汇时,门控网络会优先激活擅长情感分析的专家网络,其输出结果经加权融合形成最终响应。这种机制使得模型在保持6700亿级参数规模时,实际计算量仅需370亿参数。
技术优势体现在三个方面:计算效率提升57倍的同时保持模型容量,动态资源分配增强任务适应性,扩展性突破传统模型的线性增长瓶颈。DeepSeek-V3的实践验证了该架构的可行性,通过优化门控网络算法、实施专家负载均衡策略,将推理能耗降低至传统架构的1/8。其关键技术突破包括动态计算资源分配系统和专家冷启动预防机制。
但该架构仍面临训练复杂度陡增的挑战。专家不平衡现象导致30%的专家承担70%的计算负载,门控网络的梯度回传路径延长使训练周期增加40%。为解决这些问题,先进训练策略如专家轮换调度和梯度裁剪算法被引入。DeepSeek采用的分层训练法,先固化门控网络参数训练专家模块,再联合微调的策略,有效提升了训练稳定性。
未来发展方向聚焦于智能门控系统的演进,通过引入元学习机制使门控网络具备跨任务迁移能力,结合稀疏激活模式进一步压缩计算图谱。在自然语言处理领域,MoE架构已展现出处理长文本推理任务的独特优势,其模块化特性也为多模态融合提供了新的技术路径。随着动态路由算法和异构专家集群技术的发展,该架构有望在保持千亿参数规模的同时,实现接近传统百亿级模型的计算效率。
原文和模型
【原文链接】 阅读原文 [ 3515字 | 15分钟 ]
【原文作者】 牛山AI公园
【摘要模型】 deepseek-r1
【摘要评分】 ★★★★★


相关文章



