文章摘要
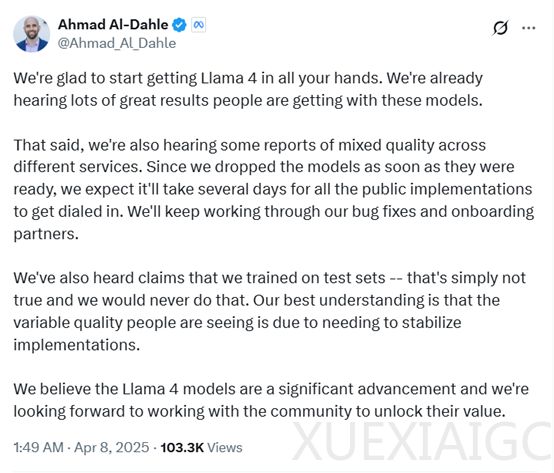
Meta生成式AI领导者Ahmad Al-Dahle针对Llama 4开源后的质疑进行了官方回应。Ahmad承认,由于模型在开发完成后立即发布,不同服务中的模型质量存在差异,并承诺将尽快修复漏洞以提升性能。他同时否认了Llama 4在测试集上进行预训练的指控,认为质量差异是由于应用实现尚未稳定化所致。Meta强调Llama 4是一项重大技术进步,并期待与社区合作挖掘其价值。
然而,Llama 4的开源并未平息质疑。有用户指出,尽管Meta在官网点名DeepSeek,称Llama 4 Maverick的代码能力可与其V3模型比肩,但实际测试结果显示,Llama 4在编程任务中的表现远不如DeepSeek V3、Grok 3等模型。无论是Scout还是Maverick模型,在实际编码任务中几乎无法使用,甚至在基础编程任务之外也频繁出错。用户认为,Llama 4的表现更像是GPT-3.5时代的模型,与当前先进模型存在明显差距。
此外,Meta的发布策略也引发了质疑。Llama 4选择在美国周六晚上发布,与以往Llama系列模型的发布时间不符,被认为是一种心虚的表现。DeepSeek的崛起给Meta带来了巨大压力,其用户和口碑正在流失,Meta急需一款重磅产品挽回局面。然而,Llama 4的表现并未达到预期,反而加剧了外界对其能力的怀疑。
在基准测试方面,尽管Llama 4在聊天机器人竞技场的大语言模型排行榜上排名第一,但用户在实际使用中发现其编程能力远低于预期。有网友质疑Meta通过刷榜提升Llama 4的排名,认为其在基准测试中的高分与实际表现不符。这种差距进一步削弱了用户对Llama 4的信任。
总体来看,Llama 4的开源并未达到Meta的预期效果,反而暴露了其在模型性能和应用实现方面的不足。Meta需要在后续优化中解决这些问题,以恢复用户对其技术的信心。同时,DeepSeek等竞争对手的崛起也表明,AI领域的竞争正在加剧,Meta必须加快创新步伐以保持领先地位。
原文和模型
【原文链接】 阅读原文 [ 1353字 | 6分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 deepseek-v3
【摘要评分】 ★★★☆☆


相关文章



