文章摘要
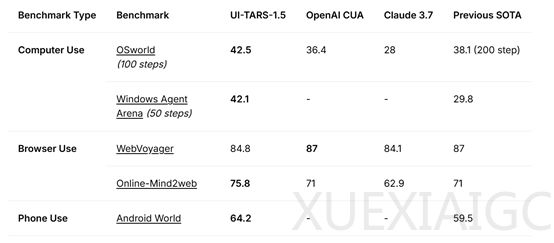
字节跳动开源了多模态AI Agent UI-TARS的最新1.5版本,该版本在多个基准测试中表现出色,展现了其强大的通用性和扩展能力。在计算机使用方面,UI-TARS-1.5在OSworld测试中得分为42.5,高于OpenAI CUA的36.4和Claude 3.7的28,Windows Agent Arena测试中得分为42.1,远超之前的29.8。浏览器使用方面,WebVoyager得分为84.8,接近OpenAI CUA和之前最高水平的87,Online-Mind2web得75.8,优于OpenAI CUA的71和Claude 3.7的62.9。手机使用方面,Android World得64.2,高于之前的59.5。
在GUI定位方面,UI-TARS-1.5在ScreenSpot-V2测试中得94.2,高于OpenAI CUA的87.9和Claude 3.7的87.6,ScreenSpotPro测试中得61.6,远超OpenAI CUA的23.4和Claude 3.7的27.7。推理时间方面,UI-TARS-1.5呈现出良好的扩展趋势,尽管并非专为Deep-research任务设计,但在两个近期具有挑战性的网页浏览基准测试中表现出了强大的通用性。SimpleQA测试中,UI-TARS-1.5为83.8,优于GPT-4.5的60,略低于带有搜索功能GPT-4o的90;BrowseComp为2.3,高于GPT4.5的0.6和GPT-4o的1.9。
游戏领域是评估多模态智能体复杂推理、决策和适应能力的关键测试环境。为评估UI-TARS-1.5的游戏能力,研究人员从poki选取了14款不同的游戏,结果显示UI-TARS-1.5在这些游戏中均取得了100的成绩,而OpenAI CUA和Claude 3.7在部分游戏中得分为0或较低。游戏的长视域特性使其成为评估推理时间可扩展性的理想选择,UI-TARS-1.5表现出强大的可扩展性和稳定性,随着交互轮次的增加,仍能保持高性能,展现出其稳健的设计和先进的推理能力。
UI-TARS-1.5能获得如此出色的性能,“统一的动作建模”是其关键创新之一,将语义上等效的动作标准化,从而实现跨平台的无缝操作和知识迁移。传统的GUI自动化工具往往依赖于特定平台的API或系统级权限来执行操作,这限制了它们的通用性和可扩展性。而UI-TARS的统一动作建模模块则摒弃了这种依赖,转而采用一种更为通用和灵活的方法。研究人员首先对各种GUI操作进行了深入分析,识别出它们的共性和差异。他们发现,尽管不同平台的操作在具体实现上可能有所不同,但在语义上往往是等效的。例如,无论是使用鼠标在Windows系统中点击一个按钮,还是在移动设备上轻触一个图标,其核心目的都是触发一个特定的功能或事件。
基于这一观察,研究人员设计了一个通用的动作空间,将这些操作抽象为一系列基本动作,如“点击”、“拖动”、“输入文本”等。这些基本动作在不同平台上具有相同的语义含义,但可以根据具体平台的特性进行适当的调整和优化。此外,研究人员还引入了一种“动作轨迹增强”技术,进一步提升了智能体的多步操作能力。在实际应用中,许多任务需要模型执行一系列连续的操作才能完成。例如,在一个电商平台上购买商品可能需要用户浏览商品页面、选择商品规格、点击“加入购物车”按钮、填写收货地址等多个步骤。为了使智能体能够更好地理解和执行这类多步任务,研究团队在数据集中添加了大量包含多个连续操作的轨迹样本。这些样本不仅记录了每个操作的具体内容,还反映了操作之间的逻辑顺序和依赖关系。通过学习这些轨迹样本,模型能够学会如何将一系列抽象动作组合起来,以完成复杂的任务。
原文和模型
【原文链接】 阅读原文 [ 1169字 | 5分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 deepseek-v3
【摘要评分】 ★★☆☆☆


相关文章



