文章摘要
【关 键 词】 AI开源、算力竞争、行业重估、资本震荡、科技竞赛
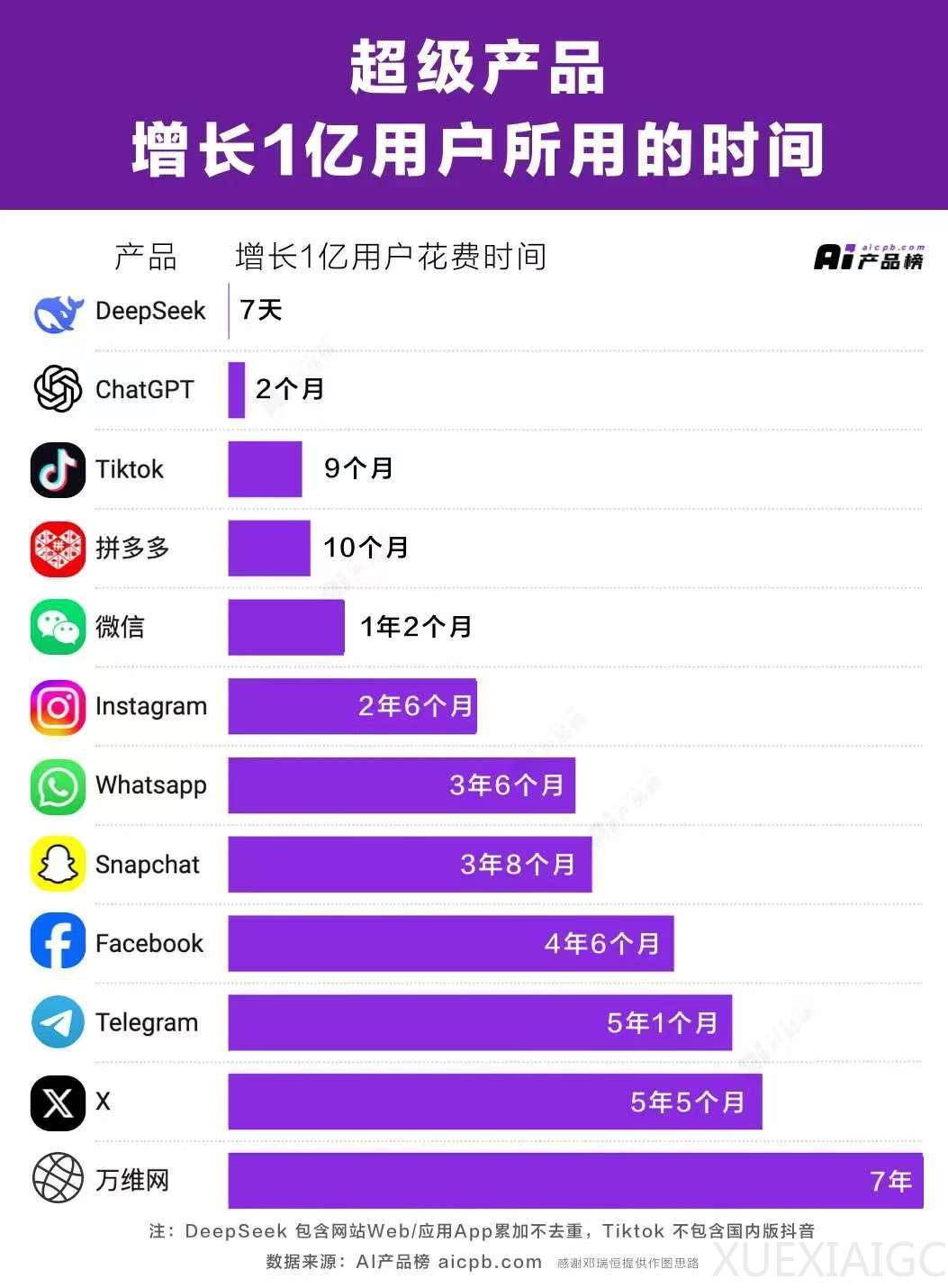
DeepSeek凭借开源技术路线和极低成本,迅速成为全球AI领域焦点。其推出的R1模型以3%的成本实现接近ChatGPT o1的性能,上线25天即突破4000万次下载,7天内新增1亿用户,直接冲击了传统科技巨头依赖算力堆砌的商业模式。这一突破导致英伟达单日市值蒸发5890亿美元,美股芯片板块集体暴跌,同时加速了全球云服务商、芯片厂商及软件公司的生态重构——微软、亚马逊、谷歌等海外云平台快速接入DeepSeek模型,华为昇腾、沐曦科技等十余家国产芯片企业完成适配,百度、阿里等国内云厂商更推出超低价方案争夺用户。
技术革新引发行业范式转变。DeepSeek通过开源RL(强化学习)和test-time scaling技术,将OpenAI的“技术黑箱”转化为可复用的公共资源,使得中小型企业能以低成本构建AI能力。这种变革催生了资本市场的连锁反应:A股36家券商发布92份相关研报,20余家科技公司股价涨停,一级市场重新关注AI硬件和传统行业嫁接AI的创业项目。未可知人工智能研究院院长杜雨指出,“所有细分赛道公司都可拥有接近免费的AI部门”,投资逻辑从技术背景转向行业整合能力。
算力竞争进入新阶段。尽管DeepSeek降低了训练成本,但推理需求的指数级增长仍推高算力消耗,其4年内总拥有成本预计达25.73亿美元。国际巨头重启“烧钱”模式:微软、谷歌等宣布年内AI资本支出超3150亿美元,OpenAI、Anthropic等融资规模持续扩大。国内华为、天数智芯加紧布局推理芯片,而Meta成立专项团队逆向研究DeepSeek技术。行业专家李广密强调,“AI产业本质仍需海量算力支撑,技术优化无法颠覆物理定律”,预示着中美算力竞赛将长期持续。
市场狂欢背后存在技术局限。DeepSeek模型依赖现有框架优化而非范式创新,其“蒸馏”技术仅降低微调成本,无法创造更强大的新模型。OpenAI、Anthropic等正加速RL研究和模型开源,试图重建技术壁垒。国内大模型公司亦筹备类似技术路线产品,但实际效果尚待验证。当前用户激增已导致DeepSeek服务器频繁过载,暴露出基础设施承压的隐患。正如投资人陈佳亭所言,“技术竞赛远未到终局,每条路线都将面临瓶颈”,行业仍处于动态博弈的早期阶段。
原文和模型
【原文链接】 阅读原文 [ 3926字 | 16分钟 ]
【原文作者】 财经天下官方账号
【摘要模型】 deepseek-r1
【摘要评分】 ★★★★☆


相关文章



